We’ll yesterday was the first time in many years that I had to spend an entire day in the office on a weekend due to a major hardware outage. This is never a good thing and it really *feels* bad when your team fails to keep core operations running smoothly. As a IT Manager, I strive for 0% unscheduled downtime and 95% up-time overall (Yep, that 5% might sound high but due to the volume of updates, backups, patches, hardware migrations, performance improvement tasks, etc… Thing need to go down for schedule work).
** I think Benjamin Franklin’s quote about a Apple a day, can be adapted to “A update a day, keeps another hacker away!”.
As for my data unavailable (DU) outage, the core symptom was our SQL Server 2008 host connect via fiber HBA to the SAN, loosing all of it’s LUNS. When my DBA saw this, she was on the phone with me in minutes yelling that all of her table had disappeared from every database in the system. She said that the system went down at 1:45 AM and all of our backups failed and all of our databases were empty except for the system tables. I immediately hopped online and realized this symptom was caused by SQL Server showing unmounted databases (why not say offline, unavailable), I’ll leave that question to Microsoft to explain…. but it definitely left her in a panic seeing all the data missing from every database on the server. Since I’m familiar with the issue (I think I’ve caused or fixed a few thousand issues, over my past 10 years of managing SQL Server), I packed the car and headed into the office.
Thinking we had DR built into our very expensive EMC SAN, I was going crazy trying to figure out why we were not online. I put in a severity 1 request with EMC telling them that we had DU and to get somebody on the phone ASAP. I grabbed a SP collect and sent it off to EMC and tech support person 1/7 found a bad fiber port on storage processor A (SP A – SFP FE 0) and said this was my issue. Since I know we have 2 storage processors, I asked him about moving the resource to B, but he said he only knew the Celerra part of our system and declined helping saying I would need to work with the Clarion tech who would be dispatched to replace SFP FE0 in 4 hours, and be on-site with parts within 24 hours. I asked multiple times if he could directly transfer me to somebody on the Clarion team to get my system online and data available, but he kept saying NO. I finally gave up on the call, so I could log some NASTY messages in the call ticket to get somebody moving ASAP (This works very well with EMC, so if you can’t get the online person to solve your problem then post all your issues, comments, and concerns in the ticketing system).
Into the server room I went, one of the few times I wish the room was a bit warmer than 67 degrees… I manually moved the host fiber cable connected to the HBA over to storage processor B and saw my LUNs show up on the HOST in seconds, but they were all showing as unrecognized and prompting for initialization. Knowing there was something wrong, I spent about a hour looking in the NaviSpehere, UniSphere, and CLI (both GUIs were new to me because 38 days prior EMC did a major update to our system). After getting half-way there, I decided to be brave to re-seat storage processor A. This ended up restoring data, but it only last for ~45 minutes before going offline again. At this point, the Clarion tech called and said he be in site in 1 hour, at 2PM with parts. Upon his arrival with a new SFP FE0 port, I asked him to first help me get online with storage processor B so we could get data available while working on storage processor A. He also didn’t know the new interface and we proceeded to go through 5 Clarion tech support people, 2 shift changes, and 4 more hours before ending up with somebody who knew what to do. As I had joked to the on-site tech a few times about it probably being 1 button or switch to set, the online tech showed us a single magic button to fix the problem! ARGH, 15 hours of downtime and 7 tech support people from EMC kept my data unavailable. The issue with the fail-over to storage processor B, was permission with the virtual disk being assigned only to storage processor A, so we moved it from A -> B and I was finally online in seconds. Since this guy seemed to KNOW the system pretty well, I asked why automatic DR fail-over did not work and why manually assigning a virtual disk to a node was needed. He realized the question meant there was else wrong, since he too was confused why this whole permission change was needed in the first place. Another hour of research from the online tech, and he determined I was missing EMC PowerPath software on all my hosts connected to the SAN via iSCSI and Fiber.
At this point, totally confused I had to get a 30 minutes lesson on PowerPath and how it works and where it was supposed to be installed. Finally, after hashing out the whole situation to determine the root cause with the; original designer, past employee who lead the project for me, my current team, Celerra support and the on-site Clarion support it was determined that the automatic fail-over features of the SAN were never setup correctly and we have never had an outage to trigger this scenario. This was a *shock* to everybody involved, but it explains a few mysterious events that have happened over the past 6 months (cluster resources becoming unavailable, complete SAN failure during upgrade, high IO on individual storage processors, etc…) that EMC support could not explain.
So, the end result and lesson learned is to always install PowerPath on all non-clustered hosts that connect to your EMC SAN if you want automatic fail-over. If you do have this setup and have a storage processor fail, follow the following steps:
1. Connect to Navisphere
2. Click “Virtual Disks”
3. Choose your virtual to edit and click the name.
4. Click “Virtual Disk Access Details”
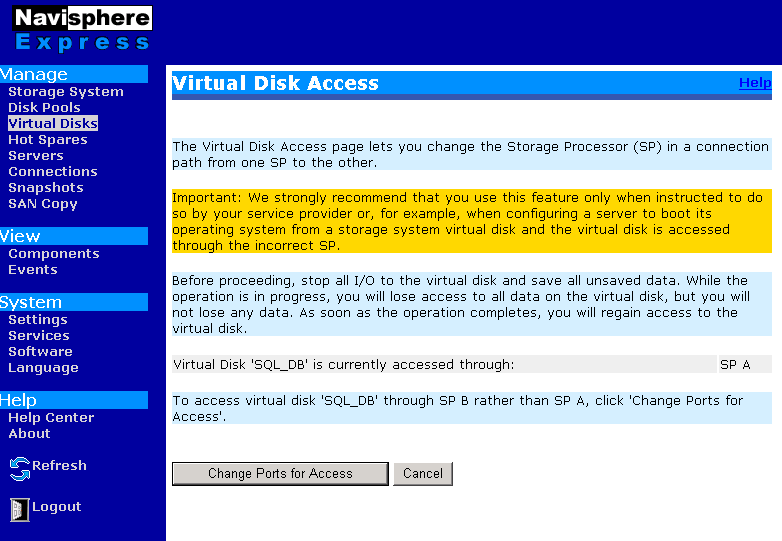
5. Click “Change Ports for Access”
** On this screen, it will show where the virtual disk is currently assigned (e.g. SP A or SP B).
That’s it, hopefully this saves somebody 15 hours of downtime confused tech support people and/or a mis-configured DR setup!